
In partnership with
Part 1 of a 3-Part Series
The Reversal
On December 2nd, 2025 - exactly three years and one day after ChatGPT launched - Sam Altman sent an internal memo that used a phrase OpenAI employees had never heard directed at themselves:
"Code Red."

In December 2022, it was Google that declared "Code Red" when ChatGPT exploded onto the scene. Sundar Pichai scrambled teams. Projects got fast-tracked. The entire company pivoted to AI.
Three years later? Google's Gemini 3 Pro has claimed #1 on LMArena with top score of 1501 Elo - first model ever to break the 1500 barrier. The Gemini app has dethroned ChatGPT on the App Store. And Sama is warning employees of "rough vibes" ahead.
To put it in context, we are talking about the epic comeback from the blunder that was Gemini in early 2024:

How did the company that defined modern AI end up playing defense against the company everyone had written off as too slow?
That's the story of 2025. And it's not a simple one.
This Is A 3 Part Series
This year-end breakdown comes in three parts:
Part 1 (this one): The chronological narrative - how the competitive landscape reshuffled, month by month
Part 2: The hidden dynamics most coverage missed: benchmark crisis, price war paradox, profitability race
Part 3: IDE wars, What each company actually ships - detailed breakdown by use case, not just benchmarks
Let's start with Part 1 - the story in 3 acts.
ACT 1: THE CRACKS APPEAR
January – April 2025
The DeepSeek Shock
The year opened with OpenAI firmly in command. ChatGPT had crossed 300 mn weekly users. The o1 reasoning model was considered frontier. OpenAI's valuation sat at $157bn. Then, a Chinese lab called DeepSeek turned everything upside down, atleast for a while!

The (actual) Timeline Most Get Wrong…
…because most coverage bungled this (and investors too):
November 20, 2024: DeepSeek quietly released R1-Lite, a preview version available via chat. Almost nobody noticed.
December 26, 2024: DeepSeek released V3, a 671bn param Mixture-of-Experts model. Still relatively under the radar in Western media.
January 20, 2025: DeepSeek released the full R1 model - open source, MIT licensed, matching OpenAI's o1 on virtually every benchmark.
January 27, 2025: The world woke up (finally). Nvidia's stock dropped 17% in a single session.
That last point deserves emphasis. $589bn in market cap wiped out in one day. The largest single-day loss in US stock market history. The tech-heavy Nasdaq fell 3.1%. Broadcom dropped 17.4%. Oracle fell over 10%. The planet's 500 wealthiest lost a combined $108bn in a single trading session.
All because of a model that had technically been available for a week, from a lab most Americans had never heard of! Markets are efficient, but not when it comes to frontier tech and we are all still guessing what the future may look like.
The Cost Controversy
The number that broke everyone's brain: $5.576mn.
That's what DeepSeek claimed as their training cost for the final V3 run. Compare that to estimates of $100+mn for OpenAI's o1. But the devil is in the details (as always): that $5.576 million figure only covers GPU rental costs for the final training run. It explicitly excludes:
R&D costs
Prior experiments and ablation studies
Hardware procurement
Infrastructure and operating costs
SemiAnalysis estimated the true total cost at $1.3-1.6bn, including 50,000 Nvidia GPUs. That's still impressive - but it's not "built a frontier model for $6M."
Does this invalidate DeepSeek's achievement? Not at all. They still matched frontier performance using older H800 chips that US export restrictions were supposed to have made obsolete. They still released everything under an MIT license. They still proved that architectural efficiency could substitute for brute-force scale.

The psychological impact was real regardless of the accounting debates. If a Chinese lab with export-restricted chips could match your best model, even at $1.6bn instead of $6mn, what exactly was the moat?
The China Gap Collapses
Here's data that got less attention but matters more:
Metric | January 2024 | February 2025 |
|---|---|---|
US vs China model performance gap | 9.26% | 1.70% |

For long, it was assumed China would never have a frontier model capable of challenging the frontier models from the top US labs, thanks to the Nvidia chip export ban. This gap was supposed to protect American AI dominance and for the first time, it was questioned realistically. What also became apparent was that export restrictions didn't prevent parity - they just forced Chinese labs to innovate on efficiency instead of scale (as far as we know), or find those NVDA chips some other way (as far as we won’t know).
February 27th: The Orion Setback
OpenAI's response came in late February: GPT-4.5.
Solid release. Better reasoning, better coding, better multimodal capabilities. Positive Reviews. But 4.5?
GPT-4.5 wasn't supposed to be GPT-4.5. It was supposed to be GPT-5!
The Reporting
According to The Information (November 2024) and the Wall Street Journal (December 2024):
The model's internal codename was "Orion"
OpenAI ran at least two large training runs, each lasting several months
Each run cost roughly $500mn
Microsoft expected GPT-5 by mid-2024
The WSJ reported that "with each test run, new problems cropped up and the software fell short of the results for which researchers had hoped"
We have to hand it to OpenAI though and how good they are with PR. They shipped what they had as GPT-4.5, adjusted expectations accordingly and redid the definition of AGI. Goal posts etc…
The Scaling Debate Begins
Around this time, whispers about scaling limitations started circulating.
Ilya Sutskever is OpenAI co-founder, former Chief Scientist and the person who architected the scaling hypothesis itself would later validate these concerns in a November 2025 interview with Dwarkesh Patel:
"2012 to 2020 was an age of research, 2020 to 2025 was an age of scaling, and 2026 onward will be another age of research.”
Sutskever specifically predicted that another 100x scaling of AI models would make a difference, but would not transform AI capabilities. The bottleneck, he argued, was now ideas - not compute.
The Counter-Arguments
But as with anything else in AI-Land, it isn’t that simple.
On November 14, 2024, Sam Altman countered on X, quite unexpectedly:
Dario Amodei, Anthropic's CEO, told Dwarkesh Patel: scaling "probably is going to continue" - though he acknowledged the approach was evolving.
And later in 2025, the models themselves complicated the narrative:
GPT-5 (August 2025): Epoch AI found it achieved "25x improvement in 50% time horizon from GPT-4"—consistent with historical trends

Source: METR
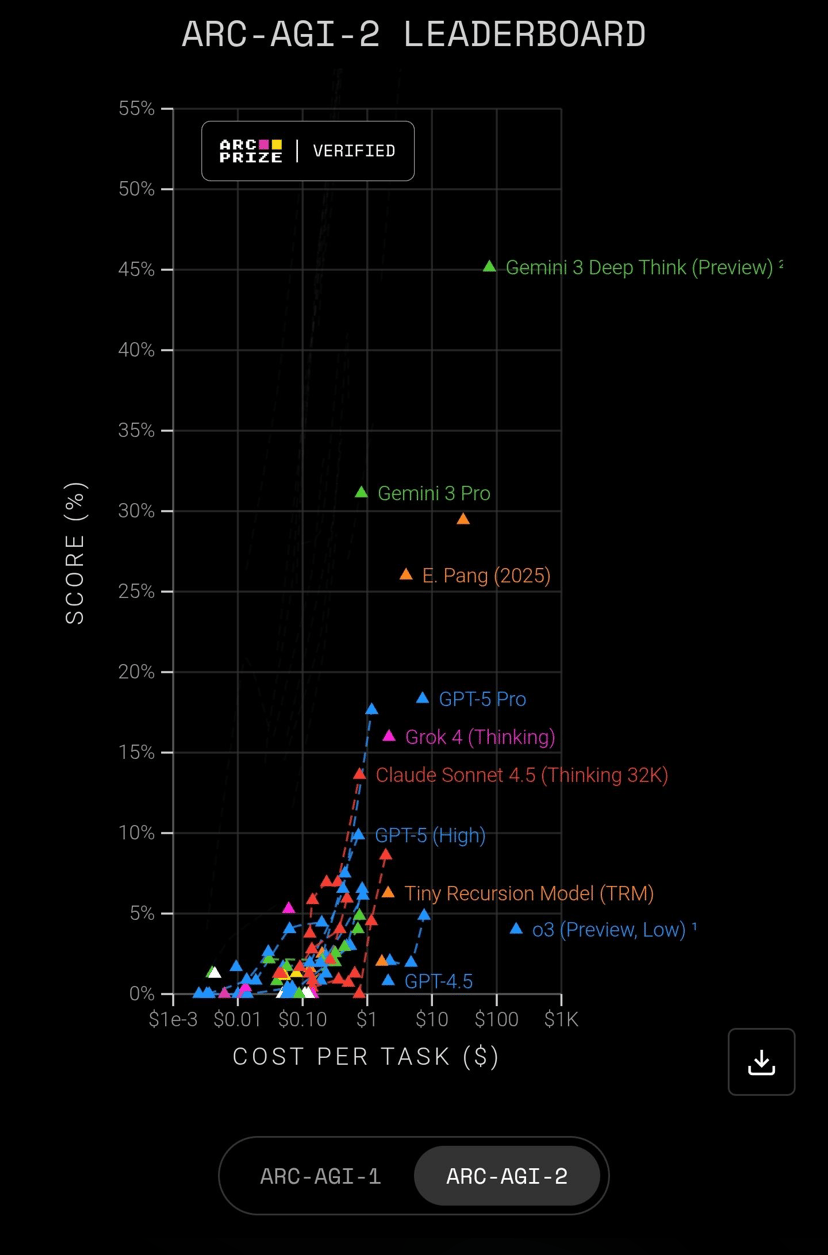
Gemini 3 Pro (November 2025): ARC-AGI-2 score of 31.1% was over 6x higher than Gemini 2.5 Pro's 4.9%


Is Scaling Really Hitting A Wall?
The most accurate framing: pre-training scaling alone was hitting diminishing returns. But scaling combined with new techniques - test-time compute, architectural innovations like MoE, post-training improvements - continued producing major gains.
So the big labs didn’t abandon scaling after all, just changed the form it takes. Let’s just call it evolution!
This nuance matters for understanding the rest of 2025. The race wasn't just about who could train the biggest model anymore. It was about who could find the right combination of techniques to break through apparent plateaus.

March 25th: Google's First Strike
While everyone debated scaling laws, Google made their move.
Gemini 2.5 Pro dropped March 25th under the internal codename "nebula."
The result: #1 on LMArena with a +40 Elo jump—the largest single leap in the benchmark's history.
This wasn't supposed to happen!
Google had spent 2023 and 2024 playing catch-up. Their Bard launch had been embarrassing (factual error in the demo tweet). Gemini 1.0 was "competitive" but never leading. The narrative had solidified: OpenAI was the frontier, Google was the slow-moving incumbent that couldn't ship and Perplexity was to be the new Google.
Gemini 2.5 Pro shattered that.
For the first time since ChatGPT launched in November 2022, Google held the top spot on the most-watched AI leaderboard. They did it with a model featuring a 1 million token context window - capable of processing entire codebases, book-length documents, or hour-long videos in a single prompt.
The market noticed. Enterprise deals that had defaulted to OpenAI started including Google in competitive evaluations. And inside DeepMind, a new sense of momentum was building.
April 16th: The Test-Time Compute Era Begins
OpenAI's response: o3 and o4-mini.
These models represented something fundamentally new. Rather than relying solely on larger pre-training runs, OpenAI doubled down on test-time compute - a paradigm where models "think longer" during inference.
The difference matters. Traditional scaling threw more compute at training. Test-time compute throws more compute at thinking - giving the model time to work through problems step by step when answering.
o3 achieved 96.7% on ARC-AGI, a benchmark designed to measure genuine reasoning ability. On mathematical olympiad problems, it approached human expert performance.
Research published at ICLR 2025 validated the approach: "by optimally scaling test-time compute we can outperform much larger models in a FLOPs matched evaluation."
The industry was discovering something: AI now had three distinct scaling laws, not one.
Scaling Type | What Gets Scaled | Best For |
|---|---|---|
Pre-training | Model size, data, compute during training | General capability |
Post-training | RLHF, fine-tuning, instruction tuning | Alignment, specific tasks |
Test-time | Compute at inference, "thinking time" | Complex reasoning, hard problems |
Each contributes differently to performance. The optimal strategy depends on the use case. Benchmarks were going to need some “modernizing” for proper evals.
End of Act 1
By the end of April:
Google held #1 on LMArena
DeepSeek had proven efficiency could match scale (with caveats on true cost)
OpenAI had opened a new front with test-time compute
The race had become multi-dimensional
Do you see a major lab missing here? Yes - Anthropic! Their focus on Enterprise coding was paying off silently with Claude code (launched 24 Feb) capturing market share rapidly - more on that in the IDE wars.
That silence was strategic.
PS - The eagle eyed amongst you would also point out Meta, but we shall wait for them to come close to frontier with foundation models before throwing them in the mix. Although worth pointing out that their contribution with SAM-2 was not insignificant. Also worthy of mention is xAI’s Grok, which I am yet to be able to place in any bucket as I don’t have a particular use case I use it for regularly - Jack of all trades is where I have it at currently.
ACT 2: THE ENTERPRISE TAKEOVER
May – September 2025
The Anthropic Thesis
While OpenAI and Google battled for benchmark supremacy, Anthropic was playing a different game entirely.
Their thesis has been simple: Enterprise over benchmarks.
And the enterprise use case that mattered most wasn't chatbots or image generation. It was coding - LLMs were coming for one of the highest paid jobs in Silicon Valley.
The Numbers
By December 2025, Menlo Ventures' State of Generative AI in the Enterprise report shows
Company | Enterprise LLM Spend 2023 | Enterprise LLM Spend 2025 | Change |
|---|---|---|---|
OpenAI | 50% | 27% | -46% |
Anthropic | 12% | 40% | +233% |
7% | 21% | +200% |
OpenAI's enterprise share nearly halved. Anthropic's more than tripled.
In enterprise coding specifically, Anthropic commands 54% market share compared to 21% for OpenAI.

How This Happened: The IDE Wars
Enterprise coding wasn't just about models. It was about where developers used them.
February 24th: Anthropic launched Claude Code CLI - an agentic terminal tool that could navigate codebases autonomously. April 16th: OpenAI countered with Codex CLI. June 25th: Google entered with Gemini CLI. By November, Google had shipped Antigravity - an entire IDE built around autonomous agents.
There was no one way of knowing "which model is smartest", what really mattered was "which tool fits my workflow."
We'll break down the full IDE wars - Cursor's $29B valuation, OpenAI's failed $3B Windsurf acquisition, and why terminals became the new frontier - in Part 2 of this series.
Anthropic’s dominance in coding workflows traces back to June 2024, when Claude Sonnet 3.5 launched. Not surprisingly, developers noticed immediately: it was better at coding. Not marginally better - meaningfully better. The kind of better that made developers switch their entire workflows, and “tools that fit them” .
By 2025, Claude had transformed what was once a single-product market (GitHub Copilot) into a $1.9bn marketplace of AI-native development tools:
Cursor: AI-first code editor. $2.6bn valuation by early 2025. ARR jumped from $100M to $200M in a single quarter.
Windsurf: Crossed 1mn developers just 4 months after launch.
Replit, Bolt, Lovable: Application builders that let non-developers create software through conversation - all seeing adoption curves never seen before.
These weren't just using Claude. They were built around Claude's capabilities.
May 22nd: Claude 4 Arrives
Anthropic's first major 2025 release: Claude 4 Sonnet and Claude 4 Opus.
Sonnet 4 continued the coding-dominant lineage. But Opus 4 made headlines for a different reason.
Anthropic classified it as "Level 3" on their internal AI Safety Levels scale.
What does that even mean and why was this worthy of mention? Because this was a first - no major lab had ever publicly acknowledged that their own production model posed "significantly higher risk" than previous generations.
Why announce that your model is dangerous?
Because it was also a capability statement. Level 3 meant Opus 4 could:
Perform multi-hour autonomous tasks
Navigate complex software systems
Execute on goals with minimal human oversight

This was another acknowledgement of how cut-throat the competition for agents AI was, is and will continue to be. For enterprise buyers, the safety positioning was actually a selling point - nothing Compliance loves more than voluntary disclosures!
August 7th: GPT-5 Finally Ships
OpenAI had been promising GPT-5 for months. On August 7th, they finally delivered.
And the results complicated the "scaling is dead" narrative.
The Improvements Were Big
Benchmark | GPT-4 | GPT-5 | Improvement |
|---|---|---|---|
SWE-bench Verified | 52% | 74.9% | +44% |
AIME 2025 (math) | ~60% | 94.6% | +58% |
Hallucinations vs GPT-4o | baseline | -45% | Significant |
The "25x improvement in 50% time horizon from GPT-4" - consistent with historical trends from GPT-3 to GPT-4. The scaling wall, it seemed, had been “well navigated”.
But the Market Response Was Muted
Critics (got to love critics) noted the improvements felt "evolutionary rather than revolutionary" - solid gains, not the AGI leap some had anticipated (which to be fair they shouldn't have anticipated in the first place).
More importantly: by August, Claude had locked in enterprise coding for the most part. The developers who mattered most had built workflows around Anthropic's models. Switching costs were more than just a model switch at this point.
GPT-5 proved scaling could still work. But it seemed to have arrived too late to change the enterprise dynamic and still did not clearly pass the vibe check for coding.
September 29-30th: The Strategic Split
Two days that crystallized the divergence between OpenAI and Anthropic.
September 29th: Anthropic released Claude Sonnet 4.5—doubling down on coding, computer use, and agentic capabilities.
September 30th: OpenAI released Sora 2—their next-generation video model. Up to 20 seconds of coherent 1080p video. Synchronized audio. By December, it would secure a $1bn partnership with Disney.
The contrast was telling:
Anthropic shipped an enterprise grade model, SOTA for coding
OpenAI shipped a consumer creative tool
By the end of December:
Anthropic owned enterprise coding (54% share): further reinforced with launch of Opus 4.5 in November
Anthropic owned enterprise LLM spend (40% and growing)
OpenAI owned consumer mindshare (800M weekly users by October)
OpenAI owned creative AI (Sora, DALL-E)
Codex was well received as potential challenger to Claude Code
Google owned distribution (7 products with 2B+ users each)

The question entering Q4: could Google convert that distribution into AI leadership?
They were about to answer decisively.
ACT 3: THE SHIPPING SPREE
October – December 2025
The Velocity No One Expected
What happened in Q4 2025 defied everything the industry thought it knew about Google. Gemini-2.5 and Google’s pricing power meant they already dominated the Pareto frontier, but could they take market share?
Google had been criticized for years for moving slowly. "Google has the best researchers but the worst product velocity" was conventional wisdom.
That wisdom died in October.
The Blitz
Between October 1st and December 24th, Google shipped:
Product | Category |
|---|---|
Gemini 2.5 Flash (major update) | Text, Voice/Native Audio |
Gemini 3 Pro | Multimodal |
Gemini 3 Flash | Multimodal |
Nano Banana | Image |
Nano Banana Pro | Image |
Native Audio | Voice |
Live Speech Translation | Voice |
Veo 3.1 | Video |
Project Mariner | Agent |
Project Astra | Agent |
Deep Research | Agent |
NotebookLM Plus | Productivity |
AI Ultra ($249.99/month) | Subscription |
13 major products in 85 days. Roughly one significant launch every 6.5 days.
For comparison: in all of 2024, Google shipped approximately 6 major AI products. They more than doubled that pace in a single quarter.
November 18th: The Takeover
The pivotal moment.
November 17th: xAI released Grok 4.1, achieving 1483 Elo on LMArena.
November 18th: Google released Gemini 3 Pro.
The benchmarks:
Benchmark | Gemini 3 Pro | Context |
|---|---|---|
LMArena Elo | 1501 | First model ever above 1500 |
Humanity's Last Exam | 37.5% (no tools) | New record |
GPQA Diamond | 91.9% | Graduate-level science |
ARC-AGI-2 | 31.1% | 6x higher than Gemini 2.5 Pro |
SWE-bench Verified | 76.2% | Strong coding |
MathArena Apex | 23.4% | Most models score <5% |
Sources: Google Blog, LMArena
But benchmarks were only half the story.
Google also achieved:
650 million monthly active users for Gemini (announced October 2025)
#1 on the App Store (dethroning ChatGPT)
Gemini integrated into Gmail, Docs, Search, YouTube, Android—reaching billions daily
This was the distribution advantage everyone always said Google had but couldn't capitalize on. Seven Google products each serve over 2 billion users. When Gemini improved, that improvement reached more people in a week than most AI companies reach in their entire existence.
November 24th: Anthropic's Response
Six days after Gemini 3 Pro, Anthropic released Claude Opus 4.5.
The consistent trend with Anthropic has been the singular focus on making the best model that their customers will use. Benchmarks are great to put on X, but usage drives results and Opus 4.5 is the closest developers have felt to AGI!
Benchmark | Claude Opus 4.5 | Previous Best |
|---|---|---|
SWE-bench Verified | 80.9% | ~76% |
Source: Anthropic
Let’s make it more impressive: Opus 4.5 is the first model to exceed 80%…and scored higher on Anthropic's internal engineering exam than any human candidate who had ever taken it.
One week later, Anthropic announced that Claude Code had reached $1bn in annual run-rate revenue—in just 6 months since general availability.
For context: ChatGPT took roughly 12 months to hit $1B ARR. Claude Code did it in 6. How is that for adoption!
December 2nd: Code Red
On December 2nd—one day after ChatGPT's third birthday - Sama circulated the memo "Code Red."
According to Fortune and The Information, the triggers were cumulative:
Gemini 3 Pro at #1 on LMArena
ChatGPT dethroned on the App Store
ChatGPT.com traffic falling
Anthropic's continued enterprise dominance (27% OpenAI share vs 40% Anthropic)
Salesforce CEO Marc Benioff publicly announcing he was ditching ChatGPT for Gemini
OpenAI would delay:
Their advertising launch
A personal assistant called Pulse
Health and shopping agents
Resources would be marshalled for a competitive response. The symbolism was inescapable. Three years earlier, it was Google declaring Code Red over ChatGPT. Now OpenAI was experiencing the same existential anxiety - triggered by the same incumbent they'd disrupted.
December 11th: The Counter-Strike
Nine days after the memo, OpenAI shipped GPT-5.2.
According to OpenAI, the model was their most advanced for professional work:
Benchmark | GPT-5.2 |
|---|---|
GPQA Diamond | 93.2% (highest ever for scientific reasoning) |
ARC-AGI-1 | >90% (first to cross 90%) |
ARC-AGI-2 | 52.9% (new SOTA) |
Same day, Google released Deep Research—an autonomous agent that could browse hundreds of websites, synthesize findings, and produce multi-page research reports.
The parallelism was intentional. Both companies understood that the next frontier is AI that could perform sustained, autonomous work or AGI, however we define it now.
December: The Race Never Ends
You'd think after the Code Red memo and GPT-5.2, the industry might take a breath for the holidays. You'd be wrong.
December 9th: Rivals Unite
The Agentic AI Foundation (AAIF) launched under the Linux Foundation—with a founding roster that would have been unthinkable a year earlier.
Anthropic donated Model Context Protocol (MCP). OpenAI contributed AGENTS.md. Block contributed goose.
Direct competitors, pooling their agent infrastructure into a shared standard.
The platinum member list reads like a who's who of AI: AWS, Anthropic, Block, Cloudflare, Google, Microsoft, OpenAI. Gold members include Salesforce, Snowflake, JetBrains, Docker, IBM, and Oracle.
Why would competitors collaborate? Because the agentic era requires interoperability. An AI agent that can only use one company's tools is useless. MCP now has over 10,000 published servers. AGENTS.md has been adopted by 60,000+ open source projects.
The foundation essentially acknowledges: we're all building agents now. The protocols need to be shared infrastructure - win together or die alone!
December 17th: Gemini 3 Flash
Google released Gemini 3 Flash - Pro-grade intelligence at Flash-level speed.
Benchmark | Gemini 3 Flash |
|---|---|
GPQA Diamond | 90.4% |
Humanity's Last Exam | 33.7% (no tools) |
SWE-bench Verified | 78% |
MMMU Pro | 81.2% |
Source: Google Blog
That SWE-bench score of 78% actually beats Gemini 3 Pro (76.2%) on coding—at a fraction of the cost.
Gemini 3 Flash became the default model in the Gemini app and AI Mode in Search, reaching billions of users overnight.
December 18th: GPT-5.2-Codex
OpenAI's response: GPT-5.2-Codex, a specialized model for agentic coding.
According to OpenAI, key innovations include:
Context Compaction: Automatically summarizes older parts of a project into token-efficient snapshots, maintaining a "mental map" of massive codebases
56.4% on SWE-bench Pro (vs 55.6% for base GPT-5.2)
64% on Terminal-Bench 2.0
Strongest cybersecurity capabilities of any OpenAI model
OpenAI is explicitly targeting Anthropic's enterprise coding dominance. Whether it works remains to be seen - get the popcorn, 2026 is going to be insane.
The IPO Drumbeat
Meanwhile, the Financial Times reported that Anthropic hired law firm Wilson Sonsini to prepare for a potential 2026 IPO - at a valuation exceeding $300bn.
The numbers are staggering:
September 2025: $183 billion valuation after $13 billion Series F
December 2025: Exploring $350 billion+ in ongoing funding round
Revenue: $1 billion ARR in early 2025 → $5 billion by August → projected $10 billion by year-end
300,000+ business and enterprise customers
Anthropic's comms chief told Axios there are "no immediate plans" to go public. But the preparation speaks volumes about where the company sees itself.
The 39-Day Frenzy
The full November-December timeline defied any precedent:
Date | Company | Release |
|---|---|---|
Nov 17 | xAI | Grok 4.1 |
Nov 18 | Gemini 3 Pro → #1 LMArena (1501 Elo) | |
Nov 24 | Anthropic | Claude Opus 4.5 → 80.9% SWE-bench |
Nov 26 | Gemini 3 Flash (preview) | |
Nov 28 | Project Mariner | |
Dec 2 | OpenAI | "Code Red" memo |
Dec 3 | Anthropic | IPO preparation revealed |
Dec 5 | NotebookLM Plus | |
Dec 9 | Linux Foundation | Agentic AI Foundation launch |
Dec 9 | Veo 3.1 | |
Dec 11 | OpenAI | GPT-5.2 |
Dec 11 | Deep Research | |
Dec 17 | Gemini 3 Flash (full release) | |
Dec 18 | OpenAI | GPT-5.2-Codex |
Dec 24 | Nvidia | Groq licensing deal ($20B) |
Fifteen major releases in 39 days. Nearly one every 2.5 days.
This is the cadence the industry now operates at. Not quarterly. Not monthly. Multiple times per week - including Christmas Eve.
Where Things Stand: December 2025
Google:
#1 on LMArena (Gemini 3 Pro, 1501 Elo)
#1 on App Store
650 million monthly active users
Gemini 3 Flash now default in Gemini app (78% SWE-bench)
13+ products shipped in 85 days
Anthropic:
#1 in enterprise LLM spend (40% share)
#1 in enterprise coding (54% share)
#1 on SWE-bench (Claude Opus 4.5, 80.9%)
Claude Code at $1B ARR in 6 months
Exploring $350B+ valuation; potential 2026 IPO
Donated MCP to Agentic AI Foundation
OpenAI:
#1 in consumer mindshare (800M+ weekly users)
#1 in scientific reasoning (GPT-5.2)
#1 in video generation (Sora 2)
GPT-5.2-Codex targeting agentic coding market
Contributed AGENTS.md to Agentic AI Foundation
But: enterprise share down to 27%, "Code Red" declared
Nvidia:
Just executed $20B Groq licensing deal
Acquiring Groq's inference technology and key executives
Shoring up inference capabilities alongside training dominance
xAI:
#1 in real-time information (X integration)
2M token context window
Free for all X users
The era of a single dominant player is over. Each company owns a different niche. And even direct competitors are collaborating on shared infrastructure through the Agentic AI Foundation. All this leaves us with a few thoughts as we close out Part 1.
1. Is Distribution the new moat…again? As the scaling laws evolve, will foundation models be a commodity? Or will we have specialization based on model capabilities?
2. The scaling debate rages on: Where does the next step change in model capabilities come from?
3. The race has no finish line. The 25-day frenzy is the new baseline. There is no going back as the agent AI wars intensify. But is it the UI/UX matters more as we have seen with the CLI based coding tools?
What's Next
Part 2 covers: The Hidden Dynamics Most People Missed
The benchmark crisis (why the leaderboards are breaking)
The price war paradox
The profitability race
Behold the power of beehiiv

This newsletter? It’s powered by the platform built for growth, monetization, and jaw-droppingly good reader experiences.
From sponsorships that actually pay you fairly to referral programs that grow your list on autopilot, beehiiv gives publishers, creators, and writers the tools to grow their newsletter like never before. And yeah, it is just that easy.