

Continued from RAG - Say what?
Today we move on to routing and query construction in what should complete the first part of the Advanced RAG pipeline. So, let’s dive in!
Routing:
Once we have the question well understood, it is time to then decide where to direct that question to. There can be multiple databases and vectorstores for your data and the answer could be in any of them. This is where routing comes in. Based on the user query and predefined choices, the LLMs can decide
a) the right data source
b) what action to perform: for example, summarizing vs doing semantic search
c) whether to execute multiple choices concurrently and collate the results (“multi routing capabilities)
Here are a few ways to “route” the query:
a) Logical routing: In this case, we let the LLM decide which part of our knowledge base to refer to, using predefined routes. This is useful for creating non-deterministic chains where the output of one step leads to the next.
b) Semantic routing: A powerful way to augment user query with prompts based on the context. This helps in quick, cost-effective decision-making by the LLMs, to choose the route to take (options can be pre-defined and custom), leading to a deterministic output.

Ok so we have the route defined by the router, are we ready to send the query across? The answer is…it depends!
The previously mentioned query translation techniques work well enough for completely unstructured datastores, but most data is housed in some form of a structured database. This implies thinking through query construction keeping in mind the kind of database.

It is easy for us to assume that LLMs interact with us in natural language. This ofcourse is not true – the datastore you are interacting defines the language that it speaks. From relational databases speaking SQL to unstructured data with associated structured matadata, the query needs to be constructed keeping in mind the query language of the database.

a. Self-query retriever (Text-to-metadata filter): Unstructured data housed in vectorstores with clear metadata files enables this retriever. Any user question (in natural language) is broken up into a query and a filter (say by year, movie, artist). By improving the quality of data sent to LLM for answering a user query, the performance of the Q&A workflow can be significantly improved.

b. Text 2 SQL: LLMs have generally been found to be quite bad at Text2SQL with a lot of startups focused on solving this issue over the last year. From creating fictitious tables and fields to misspellings in user queries, the number of ways things can go wrong is quite high. Given how common these databases are, there have been many ways that have been explored to help an LLM create an accurate SQL query. What works best can be very specific to your knowledge base, so once again there is not general rule that fits them all. Build, iterate, fix!
Create Table + Select 3: This is the most straightforward way to have a baseline of how well the model performs on your db, before jumping inot more advanced techniques. Prompt design to include a CREATE TABLE description for each table, followed by three example rows in a SELECT statement.
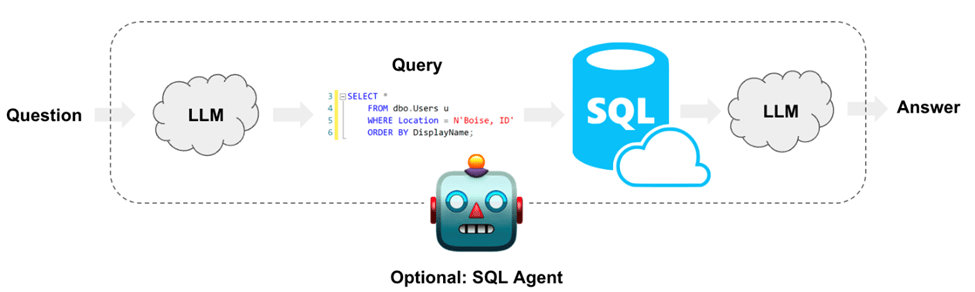
Few shot example: Provide a few Q&A pairs as examples for the LLM to understand how to build queries and you can quickly see an improvement of 10-15% on the accuracy. Scale it with more examples and it could be higher, depending on their quality and the model being used. In the latter case with many examples, it may make sense to store them in a vector store and dynamically choose a few by doing a semantic search over them for an input query.


There was also a great blog post by the good folks at anyscale outlining this sharp improvement from fine tuning, linked below for your reading:
RAG + Fine-tuning: As well outlined in the post below, fine tuned models with schema RAG and ICL can lead to 20%+ improvement in accuracy, vs just adding the entire schema to the prompt hoping the LLM will understand.
Misspelling by user: Searching proper nouns vs a vector store carrying the correct spelling can be a good way to reduce user specific errors. This was a especially annoying issue in the early days of Text2SQL.


c. Text 2 Cypher: This is specific to graph databases, which are used to express relationships that cannot be expressed in tabular forms. Cypher is the query language for such databases. The text-2-Cypher is a complex task and hence GPT4 is the recommended LLM for any such attempts.
There is a strong case to be made for Knowledge Graphs when it comes to retrieval accuracy and hence it is important to look at data formats beyond just tables and 2D schemas.

This now gets us to the point where we have explored the various techniques with query translation, construction and routing that should help us speak the language of the database that the user query should be directed to.
Up next, we shall get into the part of the workflow called Indexing, where we shall delve a bit deeper into splitting, indexing embeddings and how to set them up well for accurate retrieval.