
In our previous discussion about GraphRAG and Knowledge Graphs, we laid the groundwork for understanding these powerful data structures. Now, let's delve deeper into how we can implement these concepts in practice. We'll explore Property Graphs and their role in advancing data representation and retrieval, drawing insights from Ravi Theja’s (LlamaIndex) excellent series on Property Graphs. By the end of this post, we shall have a clear understanding of how to implement GraphRAG using LlamaIndex, complete with a practical cookbook to get you started.
The Evolution: From Knowledge Graphs to Property Graphs:
Let's begin by revisiting Knowledge Graphs (KG). At its core, a KG uses a triplet structure comprising Subject, Object, and Predicate to define relationships. Think of a KG like a basic family tree. It shows who's related to whom, but doesn't tell you much about each person.
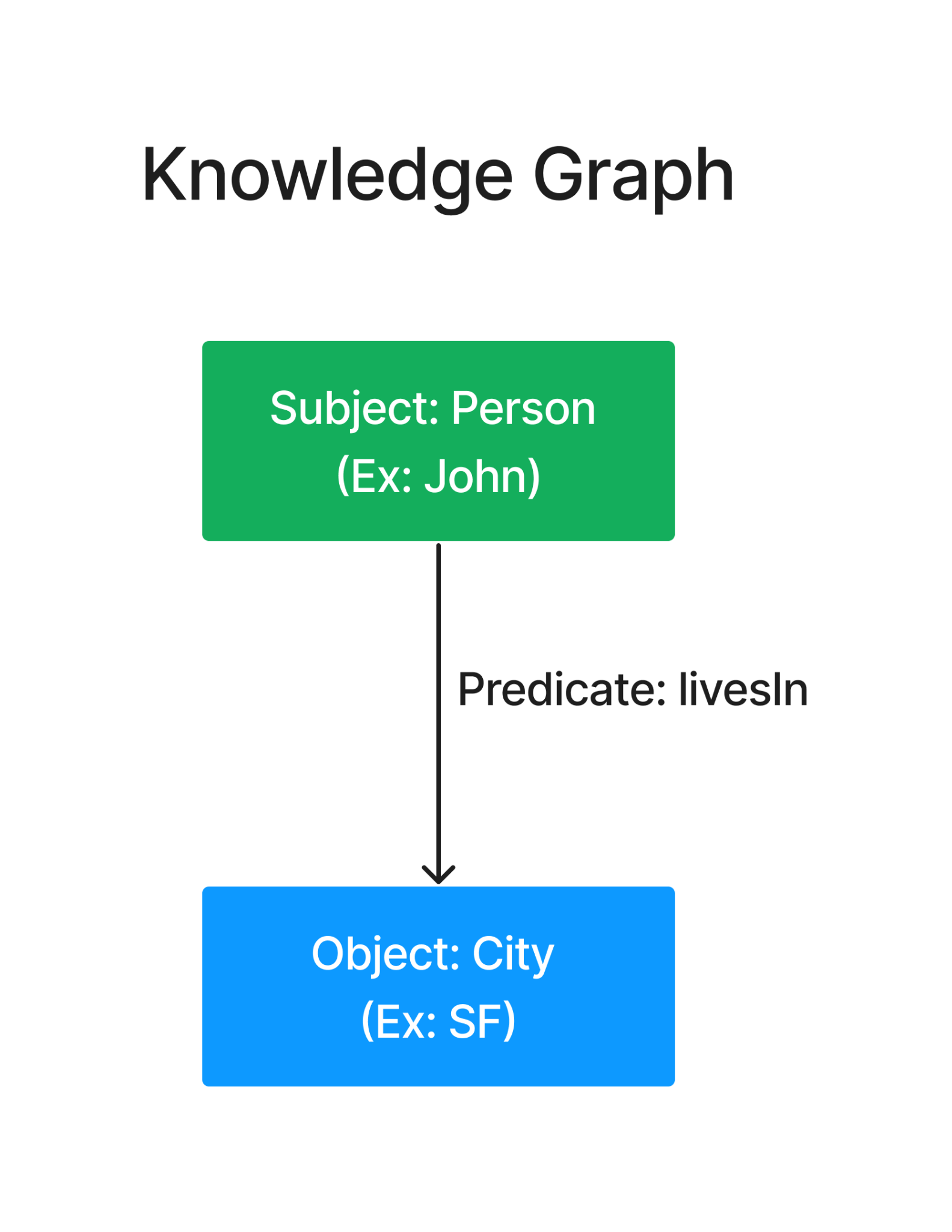
The nodes (in green and blue) have what are called “labels”, which can loosely consider to be categories, which carry certain information. They're like name tags at a family reunion. They tell you John is a person and SF is a city, but not much else. The predicate (edge) defines the relationship (and the direction) between these nodes.
Enter Property Graphs (PG): the PG structure comprises not only the subject, object and the predicate, but also properties attached to each of these entities, say name/value pairs, i.e. an upgraded family tree. It's like going from a name tag to a detailed profile for each family member.
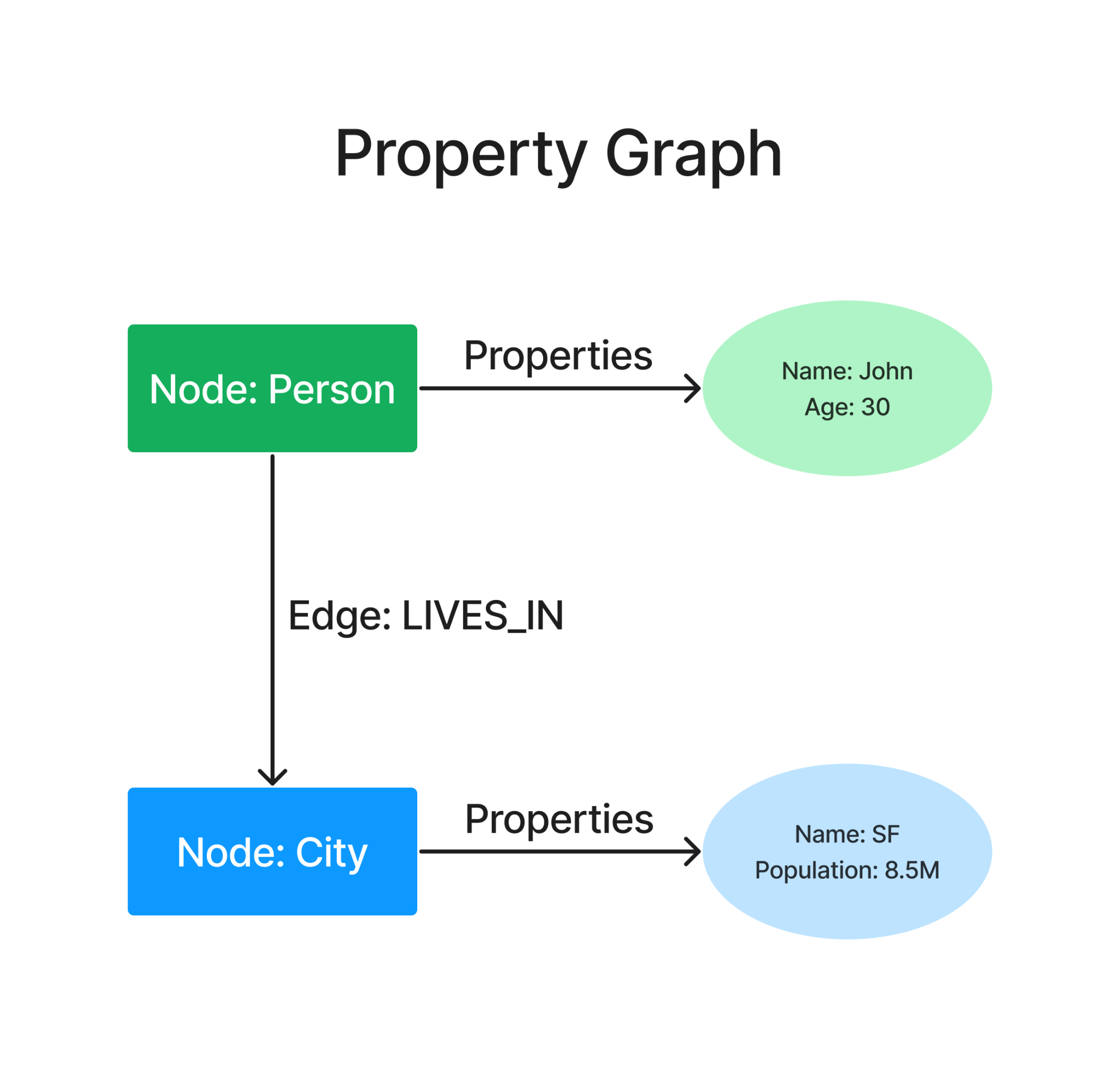
So John isn't just a person – he's 30 years old. SF isn't just a city – it's got a population of 8.5M. Interestingly, even Predicate can have properties, so the connections have details. John's link to SF? We can add that he's been there since 2006. It's like adding sticky notes to your family tree with all the details.
Building Your Property Graph: The How-To:
So, how do we turn our basic family tree into this detailed network? It's a two-step process: PG Construction and Querying. Let's break it down:

Step 1: Graph Extraction (The Construction Phase)
We've got three methods for this:
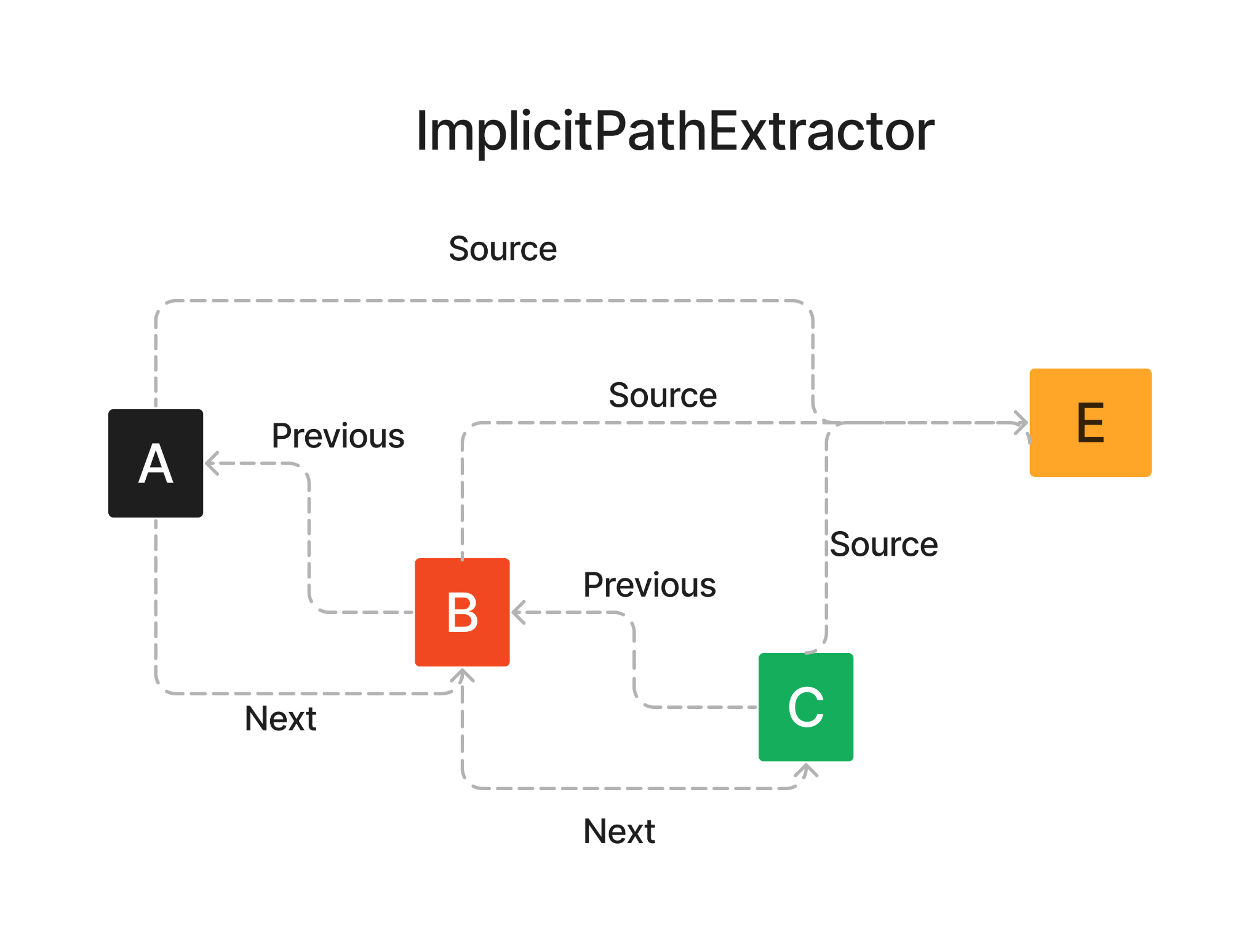
ImplicitPathExtractor: This is like organizing a bookshelf. You don't need to read every book, you just arrange them in order. In the figure below, the large text E is divided into chunks A,B and C. The relationship between the 3 chunks is defined as A comes before B, which comes before C, with all three belonging to E as the source text doc. So the ImpliciPathExtractor splits the original document into an ordered list of chunks (nodes) and their node relationships, as a lexical graph. Notably, this does not require an LLM.
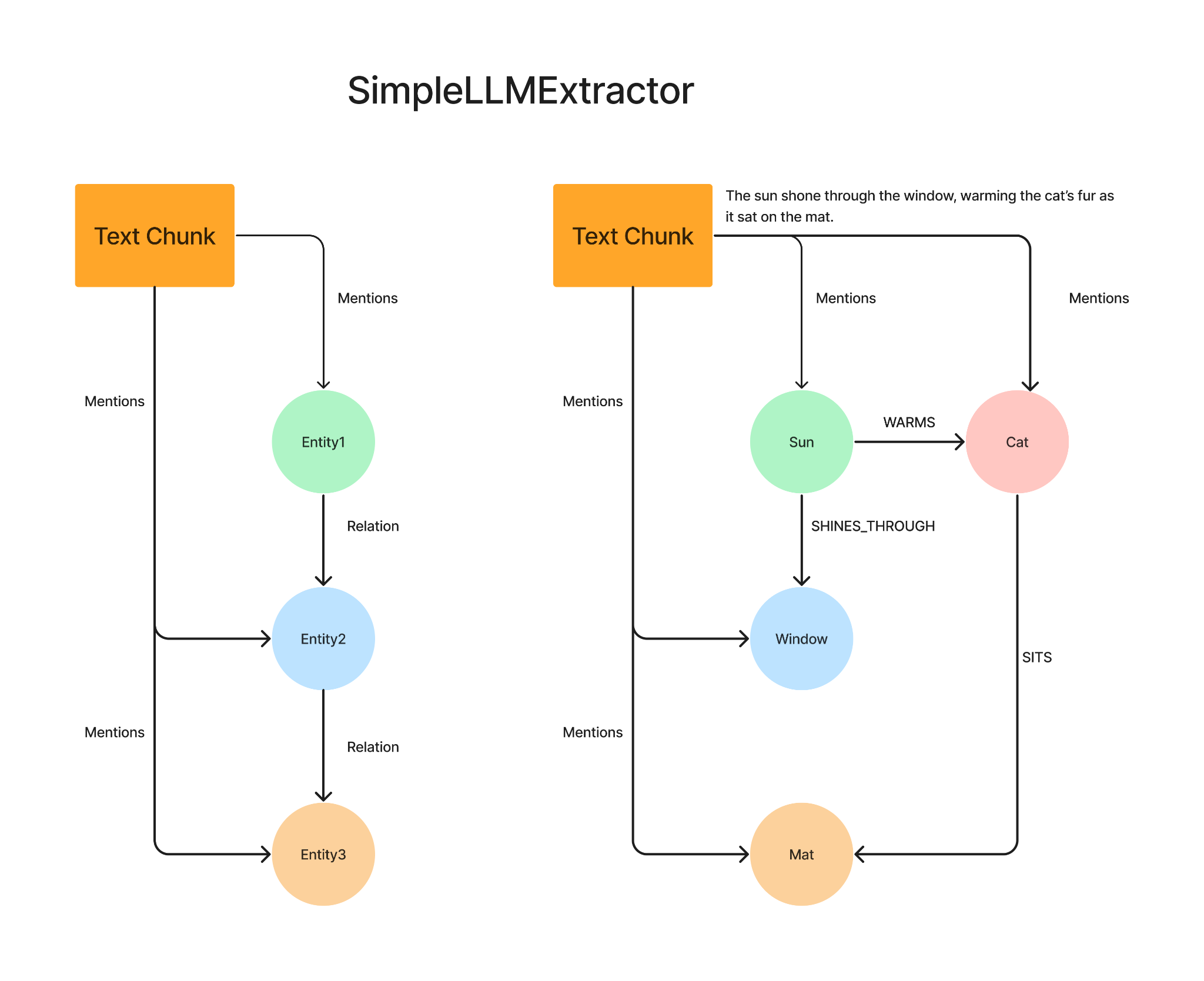
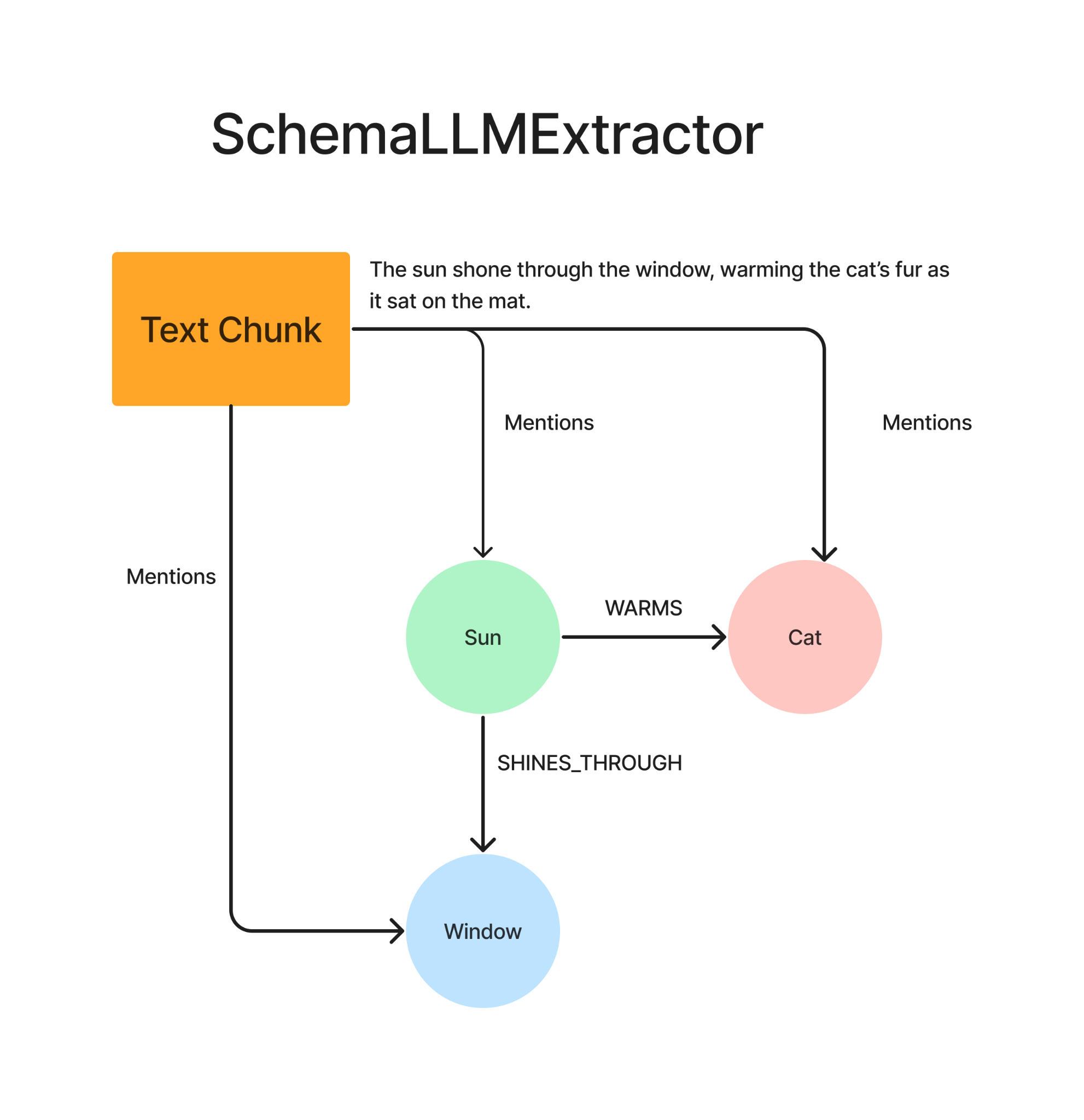
2. SimpleLLMExtractor: Imagine having a really smart friend read a book and tell you about all the characters and how they're connected. As the name suggests, here we use an LLM to extract entities and relationships from a text chunk. In the example, below we see the four entities (Sun, Cat, Window and Mat) extracted from the text chunk with relationships between them, using an LLM. The LLM here can be an open source one like Llama3, as we do not need native function calling. Note that all nodes here have the same node label, each text chunk is stored with a “mentions” relationship to each entity and these entities can further have relationships between each other.
SchemaLLMPathExtractor: This is like giving your smart friend a specific list of things to look for in the book. "Tell me about the main character, the villain, and the setting." So, while similar to SimpleLLMExtractor, it uses a pre-defined schema. We can define what entities, node labels and relationships we can extract. In our previous example, if we were to restrict the “Mat” relationship and entity, the property graph will be truncated to as we see below. Note the difference from the previous graph from SchemaLLMExtractor. It is different also in that it is best used with LLMs that support function calling and the nodes can have different node labels.
The Unsung Hero: Entity Disambiguation
While it may seem like retrieval should be the next obvious step after creating the property graph, an important and often overlooked step is “entity disambiguation”, as well documented by the good folks at neo4j. Consider this as the data cleaning step of an ETL pipeline, whereby potential duplicates can be removed using text embedding similarity and word distance. It's like making sure you're not confusing two John Smiths in your family tree. Is Uncle John the same as Cousin John? This step helps clear that up.

Step 2: Graph Retrievers (The Querying Phase)
Now that we've built this detailed family tree, how do we find information in it? We've got four tools:

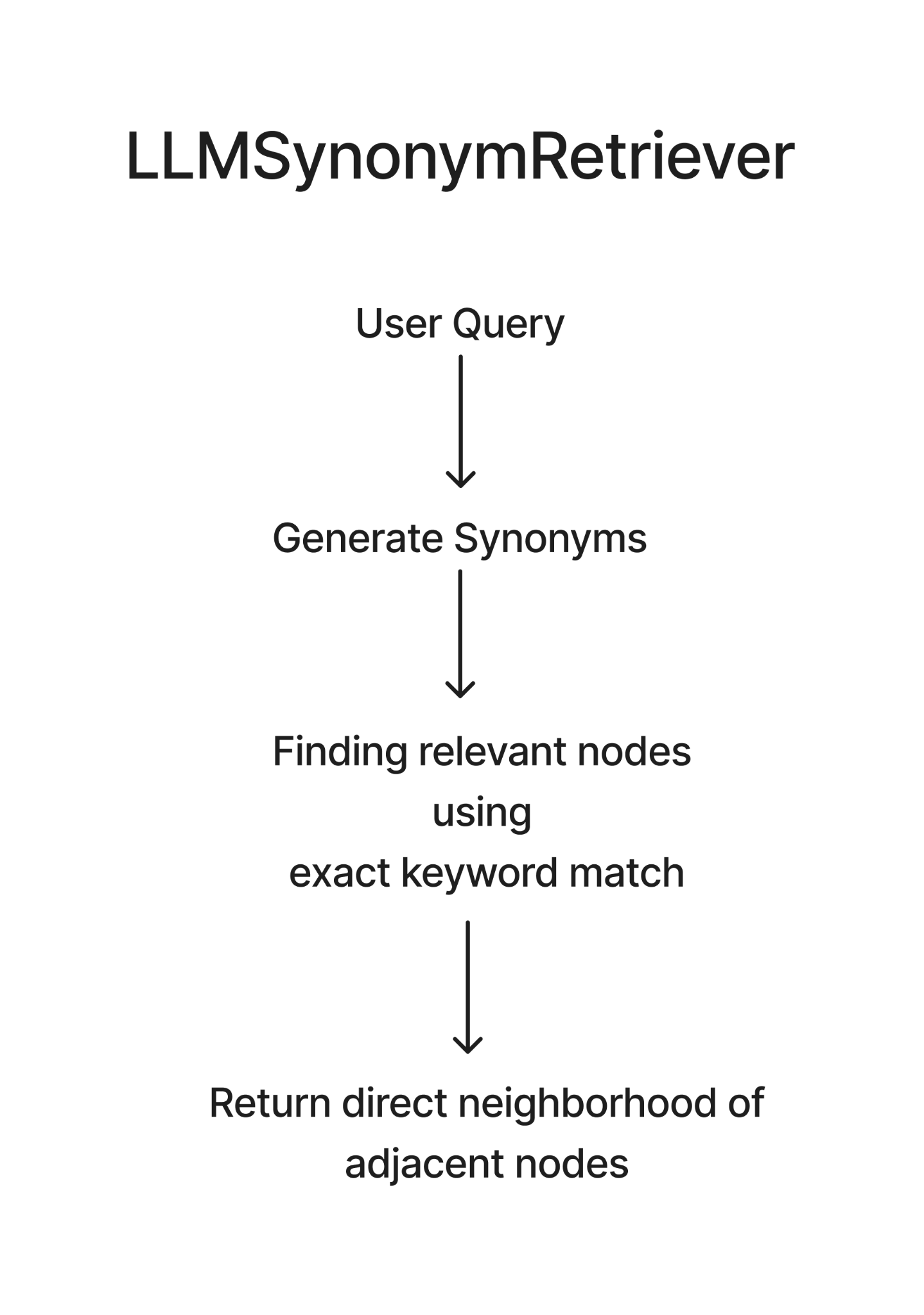
LLMSynonymRetriever: True to its name, it generates synonyms and keywords based on the user query, to get nearest nodes and their neighbors. The downside here is that it does so using a keyword search, which is not very reliable. It's like asking your aunt about family history. She might go off on tangents, but you'll get some interesting related info.
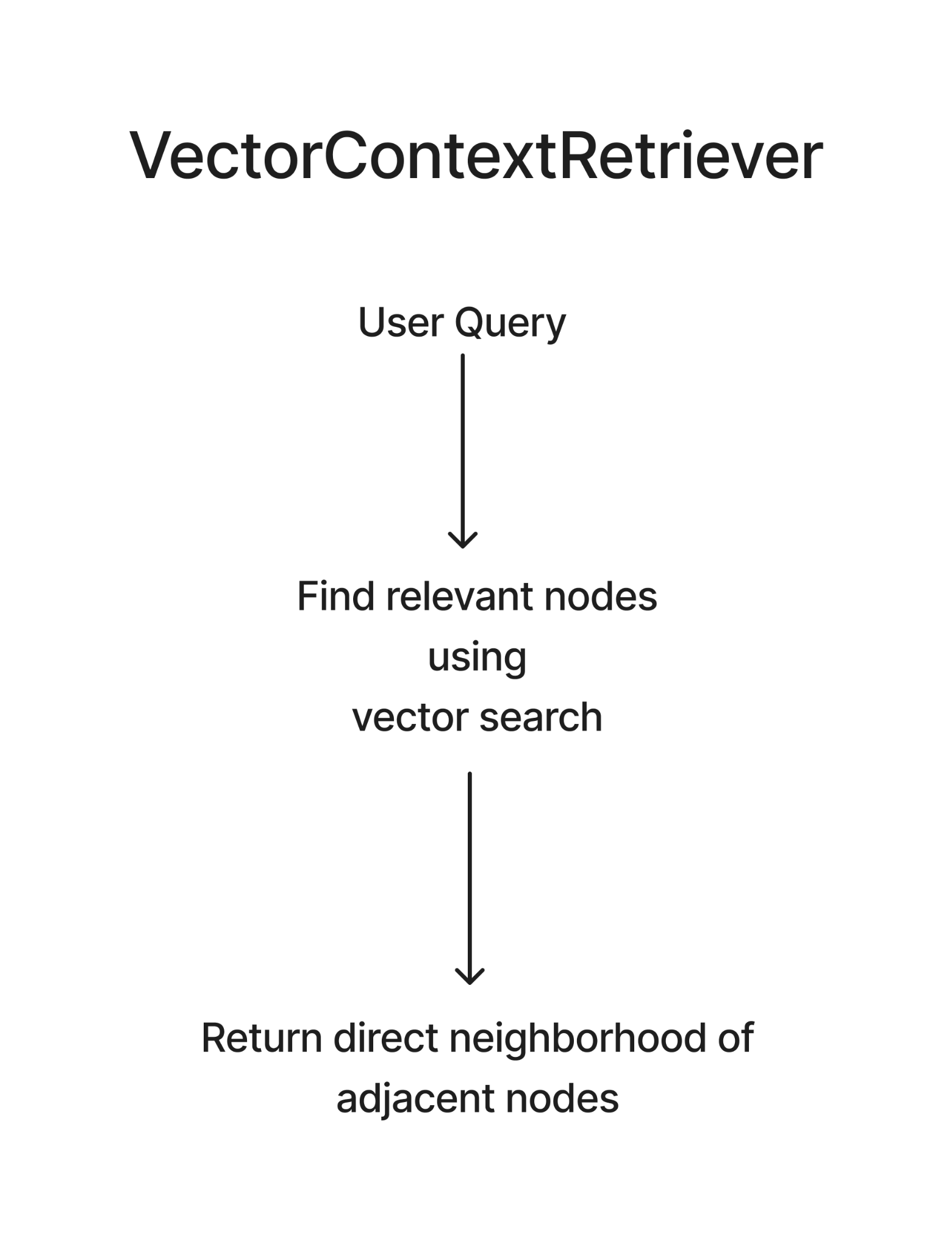
VectorContextRetriever: This retriever uses vector similarity search (using embeddings and cosine similarity) to retrieve relevant nodes. It can be used directly with graph databases, or a combination of graph and vector dbs. Notably, this is not great for global queries that may need an aggregated response, more like using a search engine for your family tree. Great for specific questions, not so great for "Tell me about our family history."
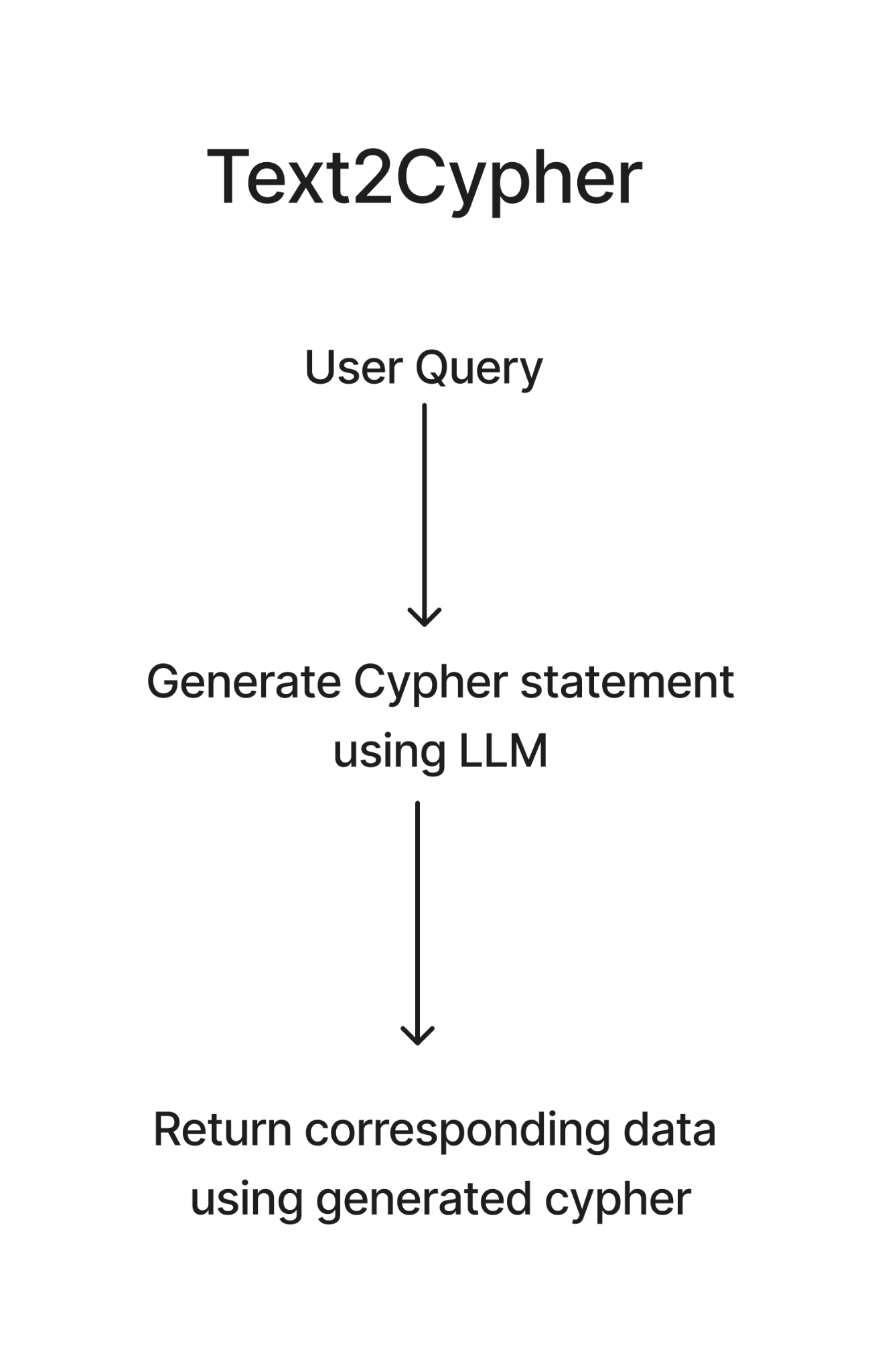
Text2Cypher: Here, we use an LLM to generate a Cypher statement based on the user query, which is then used to retrieve data from the graph db. Text2Cypher can be used for global queries that need aggregation. Hence, while it is more flexible than the previous 2 retrievers, we are still using an LLM to write Cypher statements, which may not always be accurate. It like having a translator who can turn your questions into a language your family tree understands. Sometimes the translation is spot on, sometimes it's a bit off. We are trading accuracy for flexibility, so consider using fine-tuned local models here.
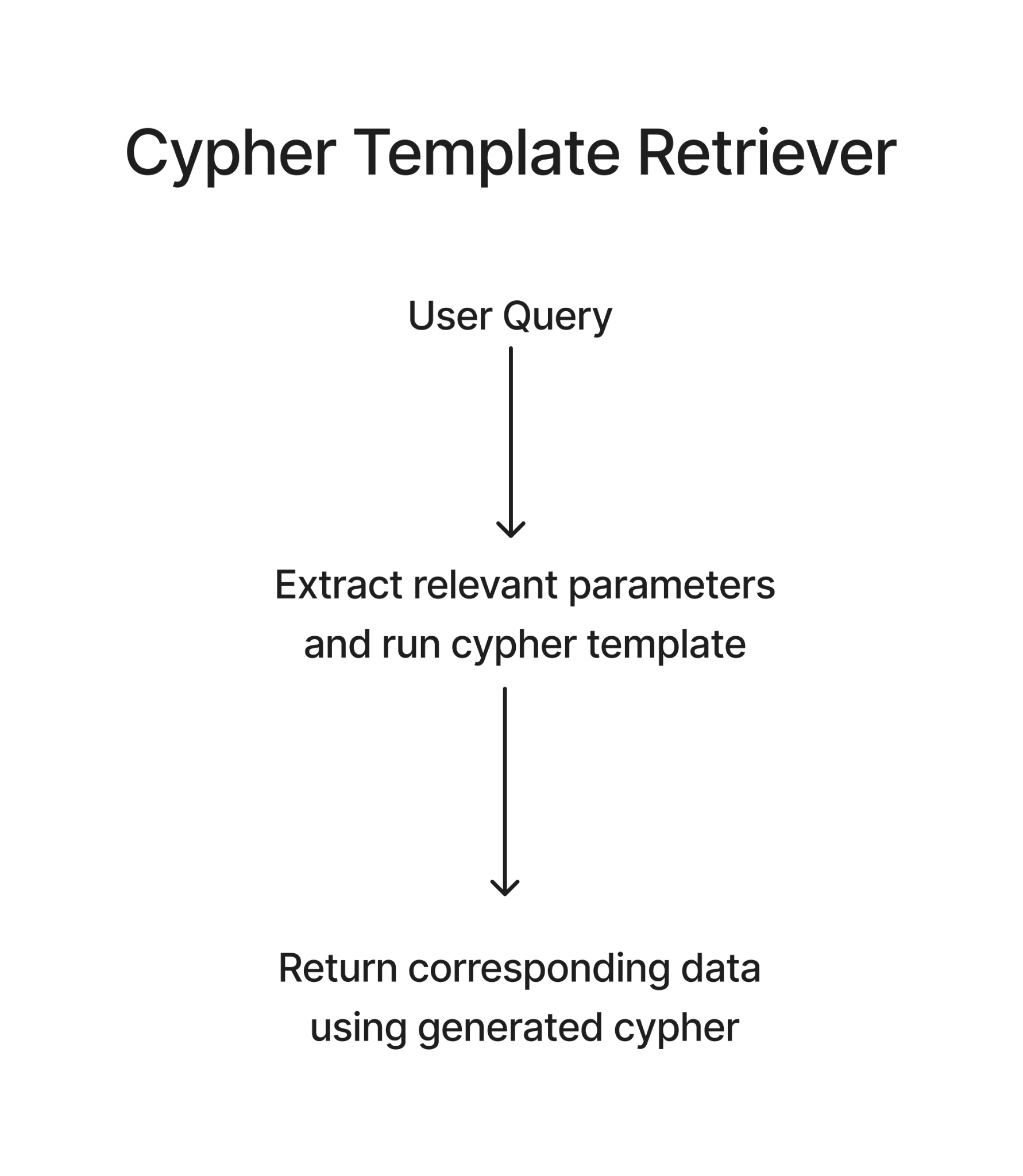
CypherTemplateRetriever: Building on the previous retriever, here we can use a Cypher template with certain parameters. For any user query, the LLM is used to populate those parameters to create a Cypher query for retrieval. This helps resolve the issue of LLM generating incorrect Cypher statements to a large extent as it is like having pre-written questions. You just fill in the blanks, reducing the chance of asking something your family tree can't understand.
Putting It All Together: GraphRAG in Action
In effect, GraphRAG is like combining your detailed family tree with a super-smart family historian. Traditional RAG (Retrieval-Augmented Generation) systems often struggle with broad, thematic questions. This is because such questions require a comprehensive understanding of the entire dataset, not just retrieval of specific pieces of information.
GraphRAG excels in scenarios where you need to:
Identify overarching themes in large datasets
Understand connections between different topics
Gain a comprehensive view of complex information landscapes
Thanks to Ravi Theja, we now have a cookbook to directly implement GraphRAG using LlamaIndex.
You can find the cookbook here! It's a practical, hands-on guide that will walk you through the implementation process step by step.
As we've explored in this post, the evolution from Knowledge Graphs to Property Graphs and GraphRAG represents a significant shift in how we think about and interact with data. While GraphRAG shows promise in areas like uncovering hidden patterns and answering open-ended questions, it's important to consider it as one of many tools in our toolkit. As with any shift in mental framework, the true value will be determined by practical applications and continued research. The cookbook above provides a good starting point to experiment with these techniques in your own data projects.
If you've had experience implementing GraphRAG or have insights to share, I encourage you to please share your thoughts and ideas in the comments section or you can reach me at:
LinkedIn: Divyanshu Dixit
Until next time, Happy reading!